 PhD student @ Peking University
PhD student @ Peking UniversityI am a fourth-year Ph.D. candidate in the Department of Computer Science at Peking University. I conduct research in the Computer Systems Research Group , co-advised by Prof. Xin Jin and Prof. Xuanzhe Liu. Prior to that, I received my B.S. in Computer Science, also from Peking University.
My research interests lie broadly in designing efficient systems for training and serving deep learning models, with a current focus on large language models (LLMs).
Outside of my academic work, I'm a passionate self-learner with a strong curiosity for various areas across computer science. I created a website called csdiy to share my self-learning experiences and curated resources with the broader community.
Warning
Problem: The current name of your GitHub Pages repository ("Solution: Please consider renaming the repository to "
http://".
However, if the current repository name is intended, you can ignore this message by removing "{% include widgets/debug_repo_name.html %}" in index.html.
Action required
Problem: The current root path of this site is "baseurl ("_config.yml.
Solution: Please set the
baseurl in _config.yml to "Education
-
Peking UniversitySchool of Computer Science
Ph.D. StudentSep. 2022 - present -
Peking UniversityB.S. in Computer ScienceSep. 2018 - Jul. 2022
Experience
-
 StepFun System TeamResearch InternJune 2024 - Apr. 2025
StepFun System TeamResearch InternJune 2024 - Apr. 2025 -
 ByteDance SeedResearch InternAug. 2023 - May 2024
ByteDance SeedResearch InternAug. 2023 - May 2024 -
 Sky Lab, UC BerkeleyResearch Intern (remote)May 2022 - Feb. 2023
Sky Lab, UC BerkeleyResearch Intern (remote)May 2022 - Feb. 2023 -
 Alibaba DAMO AcademyResearch InternSep. 2021 - Apr. 2022
Alibaba DAMO AcademyResearch InternSep. 2021 - Apr. 2022 -
AI Innovation Center, Peking UniversitySoftware Engineer InternSep. 2020 - Mar. 2021
Selected Publications (view all )

StreamRL: Scalable, Heterogeneous, and Elastic RL for LLMs with Disaggregated Stream Generation
Yinmin Zhong, Zili Zhang, Xiaoniu Song, Hanpeng Hu, Chao Jin, Bingyang Wu, Nuo Chen, Yukun Chen, Yu Zhou, Changyi Wan, Hongyu Zhou, Yimin Jiang, Yibo Zhu, Daxin Jiang
In preprint 2025
StreamRL is designed with disaggregation from first principles and fully unlocks its potential by addressing two types of performance bottlenecks in existing disaggregated RL frameworks: pipeline bubbles, caused by stage dependencies, and skewness bubbles, resulting from long-tail output length distributions. To address pipeline bubbles, StreamRL breaks the traditional stage boundary in synchronous RL algorithms through stream generation and achieves full overlapping in asynchronous RL. To address skewness bubbles, StreamRL employs an output-length ranker model to identify long-tail samples and reduces generation time via skewness-aware dispatching.
StreamRL: Scalable, Heterogeneous, and Elastic RL for LLMs with Disaggregated Stream Generation
Yinmin Zhong, Zili Zhang, Xiaoniu Song, Hanpeng Hu, Chao Jin, Bingyang Wu, Nuo Chen, Yukun Chen, Yu Zhou, Changyi Wan, Hongyu Zhou, Yimin Jiang, Yibo Zhu, Daxin Jiang
In preprint 2025
StreamRL is designed with disaggregation from first principles and fully unlocks its potential by addressing two types of performance bottlenecks in existing disaggregated RL frameworks: pipeline bubbles, caused by stage dependencies, and skewness bubbles, resulting from long-tail output length distributions. To address pipeline bubbles, StreamRL breaks the traditional stage boundary in synchronous RL algorithms through stream generation and achieves full overlapping in asynchronous RL. To address skewness bubbles, StreamRL employs an output-length ranker model to identify long-tail samples and reduces generation time via skewness-aware dispatching.
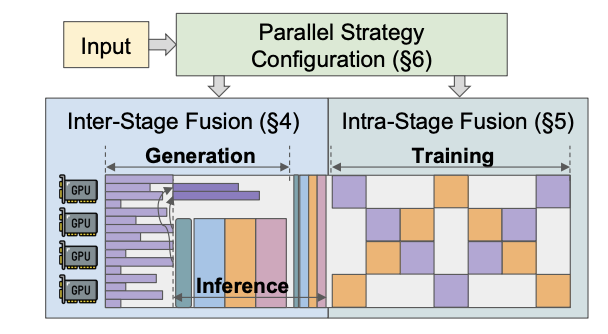
Optimizing RLHF Training for Large Language Models with Stage Fusion
Yinmin Zhong, Zili Zhang, Bingyang Wu, Shengyu Liu, Yukun Chen, Changyi Wan, Hanpeng Hu, Lei Xia, Ranchen Ming, Yibo Zhu, Xin Jin
Networking Systems Design and Implementation (NSDI) 2025
This work presents RLHFuse, an efficient RLHF training system which views the RLHF workflow from a finer-grained subtask-level perspective and opens up opportunities for efficient inter- and intra-stage fused execution, mitigating data skewness and pipeline bubbles in existing systems.
Optimizing RLHF Training for Large Language Models with Stage Fusion
Yinmin Zhong, Zili Zhang, Bingyang Wu, Shengyu Liu, Yukun Chen, Changyi Wan, Hanpeng Hu, Lei Xia, Ranchen Ming, Yibo Zhu, Xin Jin
Networking Systems Design and Implementation (NSDI) 2025
This work presents RLHFuse, an efficient RLHF training system which views the RLHF workflow from a finer-grained subtask-level perspective and opens up opportunities for efficient inter- and intra-stage fused execution, mitigating data skewness and pipeline bubbles in existing systems.

DistServe: Disaggregating Prefill and Decoding for Goodput-optimized Large Language Model Serving
Yinmin Zhong, Shengyu Liu, Junda Chen, Jianbo Hu, Yibo Zhu, Xuanzhe Liu, Xin Jin, Hao Zhang
Operating Systems Design and Implementation (OSDI) 2024
DistServe improves the performance of large language models (LLMs) serving by disaggregating the prefill and decoding computation. Given the application latency requirements, DistServe co-optimizes the resource allocation and parallelism strategy tailored for each phase.
DistServe: Disaggregating Prefill and Decoding for Goodput-optimized Large Language Model Serving
Yinmin Zhong, Shengyu Liu, Junda Chen, Jianbo Hu, Yibo Zhu, Xuanzhe Liu, Xin Jin, Hao Zhang
Operating Systems Design and Implementation (OSDI) 2024
DistServe improves the performance of large language models (LLMs) serving by disaggregating the prefill and decoding computation. Given the application latency requirements, DistServe co-optimizes the resource allocation and parallelism strategy tailored for each phase.
MegaScale: Scaling Large Language Model Training to More Than 10,000 GPUs
Ziheng Jiang*, Haibin Lin*, Yinmin Zhong*, Qi Huang, Yangrui Chen, Zhi Zhang, Yanghua Peng, Xiang Li, Cong Xie, Shibiao Nong, Yulu Jia, Sun He, Hongmin Chen, Zhihao Bai, Qi Hou, Shipeng Yan, Ding Zhou, Yiyao Sheng, Zhuo Jiang, Haohan Xu, Haoran Wei, Zhang Zhang, Pengfei Nie, Leqi Zou, Sida Zhao, Liang Xiang, Zherui Liu, Zhe Li, Xiaoying Jia, Jianxi Ye, Xin Jin, Xin Liu (* equal contribution)
Networking Systems Design and Implementation (NSDI) 2024
This paper presents the design, implementation and engineering experience in building and deploying Megascale, a production system for training large language models (LLMs) at the scale of more than 10,000 GPUs.
MegaScale: Scaling Large Language Model Training to More Than 10,000 GPUs
Ziheng Jiang*, Haibin Lin*, Yinmin Zhong*, Qi Huang, Yangrui Chen, Zhi Zhang, Yanghua Peng, Xiang Li, Cong Xie, Shibiao Nong, Yulu Jia, Sun He, Hongmin Chen, Zhihao Bai, Qi Hou, Shipeng Yan, Ding Zhou, Yiyao Sheng, Zhuo Jiang, Haohan Xu, Haoran Wei, Zhang Zhang, Pengfei Nie, Leqi Zou, Sida Zhao, Liang Xiang, Zherui Liu, Zhe Li, Xiaoying Jia, Jianxi Ye, Xin Jin, Xin Liu (* equal contribution)
Networking Systems Design and Implementation (NSDI) 2024
This paper presents the design, implementation and engineering experience in building and deploying Megascale, a production system for training large language models (LLMs) at the scale of more than 10,000 GPUs.
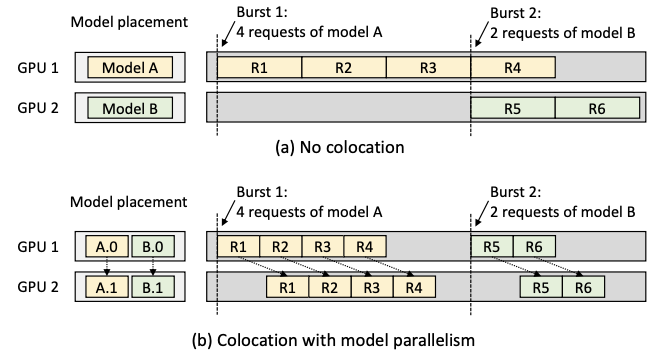
AlpaServe: Statistical Multiplexing with Model Parallelism for Deep Learning Serving
Zhuohan Li*, Lianmin Zheng*, Yinmin Zhong*, Vincent Liu, Ying Sheng, Xin Jin, Yanping Huang, Zhifeng Chen, Hao Zhang, Joseph E. Gonzalez, Ion Stoica (* equal contribution)
Operating Systems Design and Implementation (OSDI) 2023
This paper presents AlpaServe, a system for inference servings of multiple large deep-learning models. AlpaServe demonstrates that model parallelism is useful for many other scenarios, quantifies the tradeoffs, and presents techniques to automatically navigate that tradeoff space.
AlpaServe: Statistical Multiplexing with Model Parallelism for Deep Learning Serving
Zhuohan Li*, Lianmin Zheng*, Yinmin Zhong*, Vincent Liu, Ying Sheng, Xin Jin, Yanping Huang, Zhifeng Chen, Hao Zhang, Joseph E. Gonzalez, Ion Stoica (* equal contribution)
Operating Systems Design and Implementation (OSDI) 2023
This paper presents AlpaServe, a system for inference servings of multiple large deep-learning models. AlpaServe demonstrates that model parallelism is useful for many other scenarios, quantifies the tradeoffs, and presents techniques to automatically navigate that tradeoff space.