2025

DistTrain: Addressing Model and Data Heterogeneity with Disaggregated Training for Multimodal Large Language Models
Zili Zhang, Yinmin Zhong, Ranchen Ming, Hanpeng Hu, Jianjian Sun, Zheng Ge, Yibo Zhu, Xin Jin
ACM Special Interest Group on Data Communication (SIGCOMM) 2025
This work presents DistTrain, an efficient and adaptive framework to reform the training of multimodal large language models on large-scale clusters. The core of DistTrain is the disaggregated training technique that exploits the characteristics of multimodal LLM training to achieve high efficiency and scalability. Specifically, it leverages disaggregated model orchestration and disaggregated data reordering to address model and data heterogeneity respectively.
DistTrain: Addressing Model and Data Heterogeneity with Disaggregated Training for Multimodal Large Language Models
Zili Zhang, Yinmin Zhong, Ranchen Ming, Hanpeng Hu, Jianjian Sun, Zheng Ge, Yibo Zhu, Xin Jin
ACM Special Interest Group on Data Communication (SIGCOMM) 2025
This work presents DistTrain, an efficient and adaptive framework to reform the training of multimodal large language models on large-scale clusters. The core of DistTrain is the disaggregated training technique that exploits the characteristics of multimodal LLM training to achieve high efficiency and scalability. Specifically, it leverages disaggregated model orchestration and disaggregated data reordering to address model and data heterogeneity respectively.

StreamRL: Scalable, Heterogeneous, and Elastic RL for LLMs with Disaggregated Stream Generation
Yinmin Zhong, Zili Zhang, Xiaoniu Song, Hanpeng Hu, Chao Jin, Bingyang Wu, Nuo Chen, Yukun Chen, Yu Zhou, Changyi Wan, Hongyu Zhou, Yimin Jiang, Yibo Zhu, Daxin Jiang
In preprint 2025
StreamRL is designed with disaggregation from first principles and fully unlocks its potential by addressing two types of performance bottlenecks in existing disaggregated RL frameworks: pipeline bubbles, caused by stage dependencies, and skewness bubbles, resulting from long-tail output length distributions. To address pipeline bubbles, StreamRL breaks the traditional stage boundary in synchronous RL algorithms through stream generation and achieves full overlapping in asynchronous RL. To address skewness bubbles, StreamRL employs an output-length ranker model to identify long-tail samples and reduces generation time via skewness-aware dispatching.
StreamRL: Scalable, Heterogeneous, and Elastic RL for LLMs with Disaggregated Stream Generation
Yinmin Zhong, Zili Zhang, Xiaoniu Song, Hanpeng Hu, Chao Jin, Bingyang Wu, Nuo Chen, Yukun Chen, Yu Zhou, Changyi Wan, Hongyu Zhou, Yimin Jiang, Yibo Zhu, Daxin Jiang
In preprint 2025
StreamRL is designed with disaggregation from first principles and fully unlocks its potential by addressing two types of performance bottlenecks in existing disaggregated RL frameworks: pipeline bubbles, caused by stage dependencies, and skewness bubbles, resulting from long-tail output length distributions. To address pipeline bubbles, StreamRL breaks the traditional stage boundary in synchronous RL algorithms through stream generation and achieves full overlapping in asynchronous RL. To address skewness bubbles, StreamRL employs an output-length ranker model to identify long-tail samples and reduces generation time via skewness-aware dispatching.
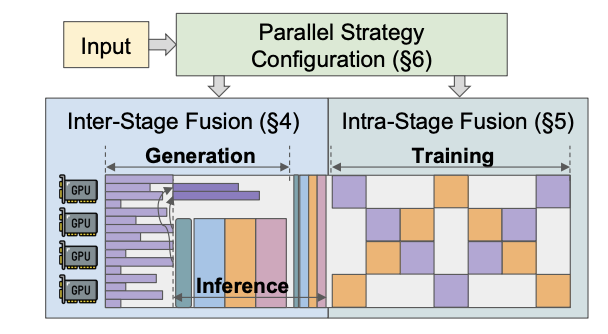
Optimizing RLHF Training for Large Language Models with Stage Fusion
Yinmin Zhong, Zili Zhang, Bingyang Wu, Shengyu Liu, Yukun Chen, Changyi Wan, Hanpeng Hu, Lei Xia, Ranchen Ming, Yibo Zhu, Xin Jin
Networking Systems Design and Implementation (NSDI) 2025
This work presents RLHFuse, an efficient RLHF training system which views the RLHF workflow from a finer-grained subtask-level perspective and opens up opportunities for efficient inter- and intra-stage fused execution, mitigating data skewness and pipeline bubbles in existing systems.
Optimizing RLHF Training for Large Language Models with Stage Fusion
Yinmin Zhong, Zili Zhang, Bingyang Wu, Shengyu Liu, Yukun Chen, Changyi Wan, Hanpeng Hu, Lei Xia, Ranchen Ming, Yibo Zhu, Xin Jin
Networking Systems Design and Implementation (NSDI) 2025
This work presents RLHFuse, an efficient RLHF training system which views the RLHF workflow from a finer-grained subtask-level perspective and opens up opportunities for efficient inter- and intra-stage fused execution, mitigating data skewness and pipeline bubbles in existing systems.
2024

LoongServe: Efficiently Serving Long-context Large Language Models with Elastic Sequence Parallelism
Bingyang Wu, Shengyu Liu, Yinmin Zhong, Peng Sun, Xuanzhe Liu, Xin Jin
Symposium on Operating Systems Principles (SOSP) 2024
This paper propose a new parallelism paradigm, elastic sequence parallelism (ESP), to elastically adapt to the variance between different requests and phases. Based on ESP, we design and build LoongServe, an LLM serving system that (1) improves computation efficiency by elastically adjusting the degree of parallelism in real-time, (2) improves communication efficiency by reducing key-value cache migration overhead and overlapping partial decoding communication with computation, and (3) improves GPU memory efficiency by reducing key-value cache fragmentation across instances.
LoongServe: Efficiently Serving Long-context Large Language Models with Elastic Sequence Parallelism
Bingyang Wu, Shengyu Liu, Yinmin Zhong, Peng Sun, Xuanzhe Liu, Xin Jin
Symposium on Operating Systems Principles (SOSP) 2024
This paper propose a new parallelism paradigm, elastic sequence parallelism (ESP), to elastically adapt to the variance between different requests and phases. Based on ESP, we design and build LoongServe, an LLM serving system that (1) improves computation efficiency by elastically adjusting the degree of parallelism in real-time, (2) improves communication efficiency by reducing key-value cache migration overhead and overlapping partial decoding communication with computation, and (3) improves GPU memory efficiency by reducing key-value cache fragmentation across instances.

DistServe: Disaggregating Prefill and Decoding for Goodput-optimized Large Language Model Serving
Yinmin Zhong, Shengyu Liu, Junda Chen, Jianbo Hu, Yibo Zhu, Xuanzhe Liu, Xin Jin, Hao Zhang
Operating Systems Design and Implementation (OSDI) 2024
DistServe improves the performance of large language models (LLMs) serving by disaggregating the prefill and decoding computation. Given the application latency requirements, DistServe co-optimizes the resource allocation and parallelism strategy tailored for each phase.
DistServe: Disaggregating Prefill and Decoding for Goodput-optimized Large Language Model Serving
Yinmin Zhong, Shengyu Liu, Junda Chen, Jianbo Hu, Yibo Zhu, Xuanzhe Liu, Xin Jin, Hao Zhang
Operating Systems Design and Implementation (OSDI) 2024
DistServe improves the performance of large language models (LLMs) serving by disaggregating the prefill and decoding computation. Given the application latency requirements, DistServe co-optimizes the resource allocation and parallelism strategy tailored for each phase.
MegaScale: Scaling Large Language Model Training to More Than 10,000 GPUs
Ziheng Jiang*, Haibin Lin*, Yinmin Zhong*, Qi Huang, Yangrui Chen, Zhi Zhang, Yanghua Peng, Xiang Li, Cong Xie, Shibiao Nong, Yulu Jia, Sun He, Hongmin Chen, Zhihao Bai, Qi Hou, Shipeng Yan, Ding Zhou, Yiyao Sheng, Zhuo Jiang, Haohan Xu, Haoran Wei, Zhang Zhang, Pengfei Nie, Leqi Zou, Sida Zhao, Liang Xiang, Zherui Liu, Zhe Li, Xiaoying Jia, Jianxi Ye, Xin Jin, Xin Liu (* equal contribution)
Networking Systems Design and Implementation (NSDI) 2024
This paper presents the design, implementation and engineering experience in building and deploying Megascale, a production system for training large language models (LLMs) at the scale of more than 10,000 GPUs.
MegaScale: Scaling Large Language Model Training to More Than 10,000 GPUs
Ziheng Jiang*, Haibin Lin*, Yinmin Zhong*, Qi Huang, Yangrui Chen, Zhi Zhang, Yanghua Peng, Xiang Li, Cong Xie, Shibiao Nong, Yulu Jia, Sun He, Hongmin Chen, Zhihao Bai, Qi Hou, Shipeng Yan, Ding Zhou, Yiyao Sheng, Zhuo Jiang, Haohan Xu, Haoran Wei, Zhang Zhang, Pengfei Nie, Leqi Zou, Sida Zhao, Liang Xiang, Zherui Liu, Zhe Li, Xiaoying Jia, Jianxi Ye, Xin Jin, Xin Liu (* equal contribution)
Networking Systems Design and Implementation (NSDI) 2024
This paper presents the design, implementation and engineering experience in building and deploying Megascale, a production system for training large language models (LLMs) at the scale of more than 10,000 GPUs.
DistMind: Efficient Resource Disaggregation for Deep Learning Workloads
Xin Jin, Zhihao Bai, Zhen Zhang, Yibo Zhu, Yinmin Zhong, Xuanzhe Liu
Transactions on Networking (TON) 2024
Deep learning (DL) systems suffer from low resource utilization due to (i) the monolithic server model that tightly couples compute and memory, and (ii) the limited sharing between different inference applications, and across inference and training, because of strict service level objectives (SLOs). To address this problem, we present DistMind, a disaggregated DL system that enables efficient multiplexing of DL applications with near- optimal resource utilization. DistMind decouples compute from host memory, and exposes the abstractions of a GPU pool and a memory pool, each of which can be independently provisioned.
DistMind: Efficient Resource Disaggregation for Deep Learning Workloads
Xin Jin, Zhihao Bai, Zhen Zhang, Yibo Zhu, Yinmin Zhong, Xuanzhe Liu
Transactions on Networking (TON) 2024
Deep learning (DL) systems suffer from low resource utilization due to (i) the monolithic server model that tightly couples compute and memory, and (ii) the limited sharing between different inference applications, and across inference and training, because of strict service level objectives (SLOs). To address this problem, we present DistMind, a disaggregated DL system that enables efficient multiplexing of DL applications with near- optimal resource utilization. DistMind decouples compute from host memory, and exposes the abstractions of a GPU pool and a memory pool, each of which can be independently provisioned.
2023
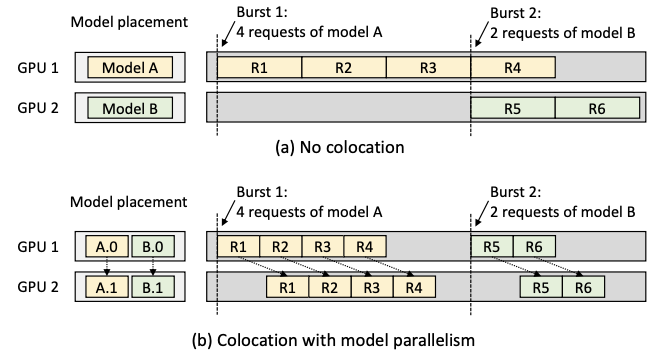
AlpaServe: Statistical Multiplexing with Model Parallelism for Deep Learning Serving
Zhuohan Li*, Lianmin Zheng*, Yinmin Zhong*, Vincent Liu, Ying Sheng, Xin Jin, Yanping Huang, Zhifeng Chen, Hao Zhang, Joseph E. Gonzalez, Ion Stoica (* equal contribution)
Operating Systems Design and Implementation (OSDI) 2023
This paper presents AlpaServe, a system for inference servings of multiple large deep-learning models. AlpaServe demonstrates that model parallelism is useful for many other scenarios, quantifies the tradeoffs, and presents techniques to automatically navigate that tradeoff space.
AlpaServe: Statistical Multiplexing with Model Parallelism for Deep Learning Serving
Zhuohan Li*, Lianmin Zheng*, Yinmin Zhong*, Vincent Liu, Ying Sheng, Xin Jin, Yanping Huang, Zhifeng Chen, Hao Zhang, Joseph E. Gonzalez, Ion Stoica (* equal contribution)
Operating Systems Design and Implementation (OSDI) 2023
This paper presents AlpaServe, a system for inference servings of multiple large deep-learning models. AlpaServe demonstrates that model parallelism is useful for many other scenarios, quantifies the tradeoffs, and presents techniques to automatically navigate that tradeoff space.
Fast Distributed Inference Serving for Large Language Models
Bingyang Wu*, Yinmin Zhong*, Zili Zhang*, Gang Huang, Xuanzhe Liu, Xin Jin (* equal contribution)
In preprint
This paper presents FastServe, a distributed inference serving system for LLMs. FastServe exploits the autoregressive pattern of LLM inference to enable preemption at the granularity of each output token. FastServe uses preemptive scheduling to minimize JCT with a novel skip-join Multi-Level Feedback Queue scheduler.
Fast Distributed Inference Serving for Large Language Models
Bingyang Wu*, Yinmin Zhong*, Zili Zhang*, Gang Huang, Xuanzhe Liu, Xin Jin (* equal contribution)
In preprint
This paper presents FastServe, a distributed inference serving system for LLMs. FastServe exploits the autoregressive pattern of LLM inference to enable preemption at the granularity of each output token. FastServe uses preemptive scheduling to minimize JCT with a novel skip-join Multi-Level Feedback Queue scheduler.
ElasticFlow: An Elastic Serverless Training Platform for Distributed Deep Learning
Diandian Gu, Yihao Zhao, Yinmin Zhong, Yifan Xiong, Zhenhua Han, Peng Cheng, Fan Yang, Gang Huang, Xin Jin, Xuanzhe Liu
Architectural Support for Programming Languages and Operating Systems (ASPLOS) 2023
This paper proposes ElasticFlow, an elastic serverless training platform for distributed deep learning. ElasticFlow provides a serverless interface with two distinct features: (i) users specify only the deep neural network (DNN) model and hyperparameters for a job, but not the number of GPUs; (ii) users specify the deadline for a job, but not the amount of time to occupy GPUs.
ElasticFlow: An Elastic Serverless Training Platform for Distributed Deep Learning
Diandian Gu, Yihao Zhao, Yinmin Zhong, Yifan Xiong, Zhenhua Han, Peng Cheng, Fan Yang, Gang Huang, Xin Jin, Xuanzhe Liu
Architectural Support for Programming Languages and Operating Systems (ASPLOS) 2023
This paper proposes ElasticFlow, an elastic serverless training platform for distributed deep learning. ElasticFlow provides a serverless interface with two distinct features: (i) users specify only the deep neural network (DNN) model and hyperparameters for a job, but not the number of GPUs; (ii) users specify the deadline for a job, but not the amount of time to occupy GPUs.